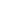


Open LLM Leaderboard 是最大的大模型和數據集社區 HuggingFace 推出的開源大模型排行榜單,基于 Eleuther AI Language Model Evaluation Harness(Eleuther AI語言模型評估框架)封裝。
由于社區在發布了大量的大型語言模型(LLM)和聊天機器人之后,往往伴隨著對其性能的夸大宣傳,很難過濾出開源社區取得的真正進展以及目前的最先進模型。因此,Hugging Face 使用 Eleuther AI語言模型評估框架對模型進行四個關鍵基準測試評估。這是一個統一的框架,用于在大量不同的評估任務上測試生成式語言模型。
Open LLM Leaderboard 的評估基準
- AI2 推理挑戰(25-shot):一組小學科學問題
- HellaSwag(10-shot):一個測試常識推理的任務,對人類來說很容易(大約95%),但對SOTA模型來說具有挑戰性。
- MMLU(5-shot)- 用于測量文本模型的多任務準確性。測試涵蓋57個任務,包括基本數學、美國歷史、計算機科學、法律等等。
- TruthfulQA(0-shot)- 用于測量模型復制在在線常見虛假信息中的傾向性。







 Telegram:
Telegram:



